Python e LLM - Guida Introduttiva Completa 2024
Pubblicato da Michele Saba
Era il 30 Novembre 2022 e OpenAI apriva al pubblico la research preview di ChatGPT, scatenando una tempesta capace di trasportare il mondo tech in quello che inizialmente sembrava essere il capitolo introduttivo di un romanzo sci fi.
A distanza di un anno possiamo dire di averne viste davvero di tutti i colori. Da chi pensava di interagire con esseri senzienti, a lettere firmate da migliaia di scienziati che chiedevano di rallentare lo sviluppo, abbiamo visto Sam Altman, CEO di OpenAI, licenziato dalla stessa board di cui faceva parte per motivi ancora non chiari per poi essere rimesso in gioco con più poteri di prima (what did Ilya see?), il blocco del servizio in Italia ad opera del garante della privacy, un'importante regolamentazione a livello Europeo relativa all'IA e tanto altro ancora.
Soprattutto, ed è di questo che parleremo in questo video, l'ecosistema dei Large Language Model (LLM) è esploso ed è in rapidissima espansione.
L'onda di ChatGPT ha portato con se importanti iniezioni di capitale che hanno contribuito allo sviluppo di modelli particolarmente performanti, capaci di rivaleggiare davvero con OpenAI. E con questi chiaramente, una serie di strumenti per il loro impiego davvero molto interessanti.
In questa guida faremo una breve introduzione al mondo dei Large Language Model nel 2024, con esempi di codice Python per l'impiego di vari modelli sia tramite API che in locale. Vedremo inoltre assieme una serie di strumenti molto interessanti pronti all'uso.
Nota: da buoni sviluppatori, il taglio che diamo al nostro contenuto è prevalentemente pratico. Il feedback costruttivo è comunque sempre apprezzato; se pensate che la guida possa essere migliorata o se pensate di aver trovato un'inesattezza, contattateci! :)
Di seguito l'indice degli argomenti:
- Oltre ChatGPT: Benchmark e Leaderboard
- Richieste alle API via Server-Sent Events (HTTP)
- API keys: come crearle, salvarle e usarle
- Come usare Claude 3 Opus di Anthropic (custom SSE client)
- Come usare GPT-4-vision (Custom SSE Client)
- Come inviare immagini: encoding Base64
- Come chattare con i modelli di Google, Mistral e Cohere (e qualche esempio di codice migliore)
- Come usare modelli GGUF con Python (tramite Llama-Cpp-Python)
- Come andare oltre? Note sugli strumenti per creare app strutturate
Oltre ChatGPT: Benchmark e Leaderboard
La quantità di modelli linguistici attualmente presenti e disponibili sul mercato è davvero molto elevata. Nonostante molto meno diffuso a livello consumer di quanto si possa pensare, se state leggendo queste righe avrete chiaramente sentito parlare di ChatGPT, attualmente basato sul modello GPT-4. È molto probabile che mentre leggete questa guida siano inoltre già presenti le versioni GPT-4.5 (che mi aspetto entro fine Giugno 2024) o addirittura la GPT-5. Voglio comunque precisare che ciò che vedremo in questo video dovrebbe rimanere rilevante anche per quei modelli, con modifiche minime.
Oltre a ChatGPT, verosimilmente conoscerete anche Gemini, il modello di Google. Abbiamo poi i modelli di Anthropic, che ha recentemente aperto al pubblico Claude 3, considerato da molti il primo Large Language Model effettivamente capace di superare GPT-4. Aggiungiamo alla lista dei "Fantastici 4" (licenza poetica :)) anche i modelli di Mistral AI, un'azienda francese che ha prodotto dei modelli davvero molto interessanti. Parte di questi sono "open" e quindi disponibili al download gratuito, così da poterli far girare direttamente nel nostro computer; vedremo come fare. Ma non finisce qui, in quanto è presente anche tutta una famiglia di modelli derivati dai modelli LLaMA di Meta (ex Facebook). Oltre che i modelli sviluppati in Cina, quelli in arrivo dall'India... e così via.
Quindi, se ci sono così tanti modelli, quali dovremmo effettivamente scegliere di utilizzare? La risposta più realista è forse che dipende da ciò che ci dovete fare con questi modelli, in quanto tra questi cambiano non solo le performance effettive a livello di risoluzione dei task assegnati, ma cambiano anche effettivamente quelli che sono i termini di utilizzo di questi modelli! Cercando di mantenere il tutto quanto più conciso possibile, la risposta a quale tra questi può essere il migliore può essere trovata nei benchmark di valutazione e nelle "leaderboard". Se avete dato uno sguardo alle pagine di presentazione (esempio Claude 3, esempio Mistral Large) o ai paper relativi ai vari modelli che vengono rilasciati, troverete spesso che sono presenti dei benchmark che mettono a confronto vari modelli sulla base di punteggio ottenuti in test relativi, ad esempio, a capacità di ragionamento, conoscenza, buon senso...
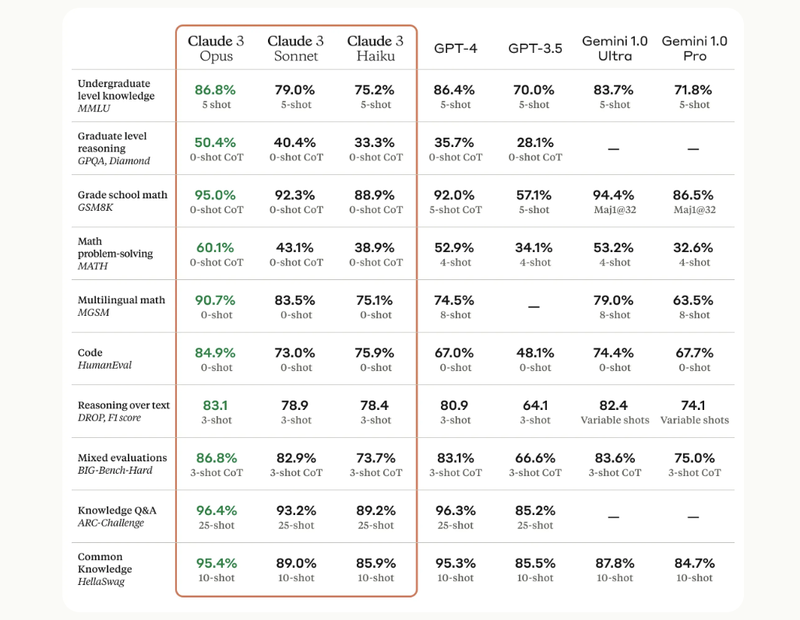
Oltre ai test di valutazione sopra citati, ci si può fare un'idea anche a partire da "arene", dove è possibile far "sfidare" più modelli contemporaneamente in modo da poterne paragonare i risultati in maniera anonima. Ciascun modello avrà a quel punto un punteggio sotto forma di Elo rating (simile quindi al sistema di rating degli scacchi) che ci dirà quale dei modelli attualmente disponibili sia effettivamente quello che, umanamente parlando, potrebbe essere il migliore. La classifica è attualmente dominata da modelli che hanno una licenza proprietaria. Dobbiamo scorrere un bel po' prima di trovare una licenza open, dove troviamo un modello di Mistral chiamato Mixtral 8x7B, basato sull'architettura Mixture of Experts, rilasciato sotto licenza Apache 2.0.
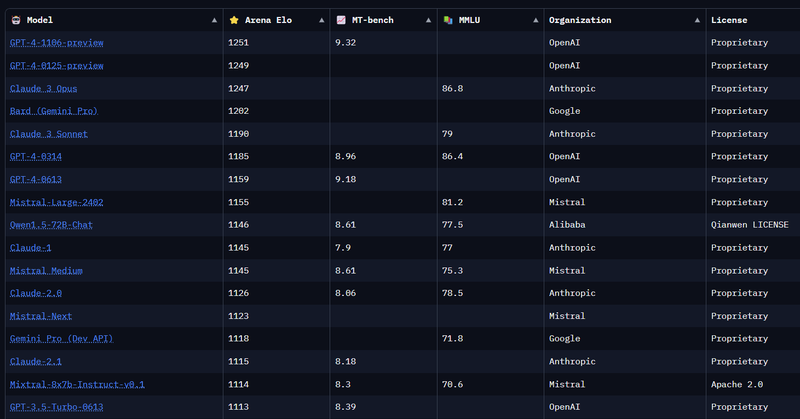
È inoltre presente una leaderboard per i modelli Open, hostata su HuggingFace.
Quindi che modello scegliere? Ritengo opportuno porsi una domanda più utile perché foriera di risvolti pratici: cosa dobbiamo farci?
I modelli in testa alle leaderboard "globali" sono chiaramente i più performanti nella gran parte dei casi, per cui dovreste andare a colpo sicuro. Ma hanno come pecca il fatto che per natura intrinseca del servizio offerto, dovrete inviare i vostri dati alle aziende che li mettono a disposizione, con tutte le considerazioni in merito a privacy e proprietà intellettuale che ne conseguono. Senza considerare che questi servizi sono offerti a pagamento, e che quindi costruire qualcosa attorno a questi potrebbe ridurre sensibilmente i vostri margini di profitto.
D'altro canto i modelli open source iniziano a diventare anch'essi molto interessanti. E se è vero che i più performanti richiedono per il loro utilizzo risorse hardware considerevoli, è vero anche che se il task che volete svolgere non è particolarmente complicato o non richiede la massima accuratezza, dovreste poter utilizzare uno di questi modelli open source anche su macchine di livello consumer; per comprenderci, anche sul vostro laptop di qualche anno fa! Nel "catalogo" open source troviamo infatti modelli di dimensioni modeste ma comunque di tutto rispetto, come quelli a 7 miliardi di parametri (modelli 7B), che dovrebbero girare al giorno d'oggi sostanzialmente nei computer di tutti - vedremo come fare più avanti, impiegando appena qualche riga di codice Python.
Esistono inoltre modelli "puramente" linguistici e modelli multimodali, poi ci sono modelli che sono passati per fasi di addestramento specializzate... ancora: cosa volete farci?
In generale non c'è quindi una risposta definitiva alla domanda, senza prima contornare la stessa con tutte le informazioni di contesto necessarie alla scelta di un qualsiasi strumento. Leaderboard e benchmark sono comunque un buon punto di inizio per la costruzione di un ponte tra specifiche di progetto e scelta di una soluzione, oltre che uno snapshot sempre attuale dello stato dell'ecosistema.
Richieste alle API via Server-Sent Events (HTTP)
Prima di vedere come impiegare Python per usare modelli linguistici open source nei nostri computer, vediamo come sia possibile utilizzare i modelli di Anthropic, OpenAI, Mistral e Google nei nostri programmi e script senza bisogno di utilizzare i client ufficiali messi a disposizione dalle singole aziende.
Nonostante i client ufficiali siano la scelta giusta nella gran parte dei casi (ne abbiamo parlato in un'altra video guida), abbiamo optato per mostrare come fare ciò in maniera quanto più pura possibile così che, una volta appreso il meccanismo di comunicazione con questi servizi, sarà poi facile applicare la stessa conoscenza per comunicare con la gran parte dei modelli attualmente disponibili e, verosimilmente, anche con la gran parte di quelli che verranno messi a disposizione nel prossimo futuro.
Le API dei provider utilizzano uno standard chiamato Server-Sent Events. Viene utilizzato per permettere ai server web di inviare aggiornamenti in tempo reale ai propri client. Dopo che il client inizializza la connessione mediante una richiesta HTTP standard, il server mantiene questa aperta e utilizza questa "connessione persistente" per inviare eventi di aggiornamento non appena si rendono disponibili. La natura unidirezionale e la semplicità del protocollo fanno di SSE una scelta efficace per applicazioni che necessitano di ricevere aggiornamenti in tempo reale.
Nel caso dei servizi che permettono l'impiego dei Large Language Model tramite REST API, l'uso di questi in modalità "streaming" ci permette di iniziare a ricevere i vari pezzi delle risposte mano mano che vengono generate; questo si dimostra molto comodo in quanto a seconda del numero di token da elaborare e del livello di carico dell'infrastruttura, la generazione della risposta completa potrebbe richiedere parecchio tempo. Peccato quasi mortale nell'era di Instagram e TikTok.
API Keys: come crearle, salvarle e usarle
La prima cosa di cui avrete bisogno è un'API key, ovvero la chiave necessaria ad autenticarvi col provider. Si tratterà, nel concreto, di una stringa di caratteri reperibile in questo caso dal portale per sviluppatori di Anthropic e associata al vostro account. Se l'interfaccia web non dovesse essere accessibile dall'Italia dovreste comunque essere in grado di ottenere la chiave connettendovi sotto VPN. Visto che questa domanda ci viene posta spesso la risposta è si: dovrete acquistare dei crediti per comunicare con la gran parte di questi servizi! Usare i modelli di punta di Anthropic e OpenAI potrebbe essere considerato abbastanza costoso a seconda del lavoro che intendete svolgere. Il modello Gemini Pro di Google è invece, al momento della scrittura di questa guida, gratuito fino a 60 richieste al minuto. Mentre i servizi di Mistral sono estremamente economici.
Di seguito i link da seguire per poter generare le necessarie API key per i principali modelli, dai portali per sviluppatori dei vari provider:
Salvate l'API key all'interno di un file json, che potrete quindi escludere dal versioning in modo da evitare la diffusione accidentale. Nel nostro caso chiamiamo questo file "secrets.json".
Utilizziamo la funzione get_api_key() salvata in un file chiamato auth_keys.py. Questa accetta come parametro la stringa provider, restituendo il valore assegnato alla chiave nello stesso file:
# auth_keys.py
import json
def get_api_key(provider: str) -> str:
with open("secrets.json", "r") as f:
secrets = json.load(f)
return secrets[provider]
# esempio del contenuto del file secrets.json
{
"OPENAI_API_KEY": "api-key-di-openai",
"MISTRAL_API_KEY": "api-key-di-mistral",
"GOOGLE_API_KEY": "api-key-di-google-ai",
"ANTHROPIC_API_KEY": "api-key-di-anthropic"
}Come usare Claude 3 Opus di Anthropic (custom SSE client)
Ora che disponiamo della nostra API key possiamo finalmente passare al codice necessario per poter comunicare col modello Claude 3 Opus di Anthropic (o uno dei due fratelli minori della famiglia Claude 3). A primo impatto, il codice potrebbe sembrare complicato, ma è in realtà piuttosto semplice da comprendere. Analizziamolo.
Importiamo i moduli request e sseclient-py dopo averli installati all'interno di un ambiente virtuale. Importiamo anche il modulo json della standard library e la funzione get_api_key() dal nostro modulo auth_keys.
Definiamo quindi una serie di variabili per impostare i dettagli necessari ad effettuare ogni singola richiesta. È importante comprendere che i valori assegnati a queste variabili vanno cercati nella documentazione ufficiale di ogni provider.
L'api_endpoint rappresenta l'indirizzo dove inviare le richieste, model_name lo specifico LLM con cui intendiamo interagire, temperature rappresenta il "livello di creatività" che vogliamo venga usato per le risposte del modello (0 poco creativo, 1 molto creativo), mentre gli header rappresentano informazioni aggiuntive necessarie per la richiesta. Notiamo come tra gli header, nel caso di Anthropic, passiamo il valore della nostra API Key via "x-api-key", autenticando in questo modo la richiesta.
Notiamo poi come venga inizializzata la chat_history, ovvero lo storico dei messaggi scambiati tra noi e il modello, come una lista vuota.
Avviamo un ciclo infinito, che useremo per il nostro scambio di messaggi: invio, ricezione risposta, presentazione della risposta.
Nello specifico:
- richiediamo all'utente di inserire un messaggio.
- aggiungiamo il messaggio alla chat history con role: user, permettendoci di distinguere i nostri messaggi da quelli del modello, che hanno invece role: assistant
- inizializziamo un dizionario data, che conterrà i dati da inviare ad ogni singola richiesta. stream: True informerà l'API di Anthropic che desideriamo ricevere la risposta via stream SSE, mentre con max_tokens definiamo la lunghezza massima desiderata per ogni risposta.
A questo punto siamo finalmente pronti per effettuare una richiesta di tipo POST sull'endpoint sopra definito. Se il response avrà status code 200, sapremo che la richiesta sarà andata a buon fine.
Potremo quindi inizializzare un oggetto SSEClient per gestire i vari eventi dello stream; avviamo un ciclo for e per ogni singolo evento ricevuto presentiamo all'utente il singolo pezzetto di risposta tramite funzione print(). Oltre a presentare i dati all'utente ricomponiamo il messaggio completo cosi che possa essere aggiunto alla chat_history.
# demo_api_claude.py
import json
from sseclient import SSEClient
import requests
from auth_keys import get_api_key
api_key = get_api_key("ANTHROPIC_API_KEY")
api_endpoint = "https://api.anthropic.com/v1/messages"
model_name = "claude-3-opus-20240229"
temperature = 0.0 # 1.0
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"anthropic-version": "2023-06-01",
"anthropic-beta": "messages-2023-12-15",
"x-api-key": api_key
}
chat_history = []
while True:
user_query = input(">>> ")
print()
chat_history.append({
"role": "user", "content": user_query
})
data = {
"model": model_name,
"messages": chat_history,
"temperature": temperature,
"stream": True,
"max_tokens": 2048 # potete variare!
}
response = requests.post(
api_endpoint,
headers=headers,
json=data,
stream=True
)
lm_response = ""
if response.status_code == 200:
stream = SSEClient(event_source=response)
for event in stream.events():
event_data = json.loads(event.data)
if event_data["type"] == "content_block_delta":
response_piece = event_data["delta"]["text"]
lm_response += response_piece
print(response_piece, end="", flush=True)
chat_history.append({
"role": "assistant", "content": lm_response
})
else:
print(response.status_code)
print("\n")# esempio di un flusso di risposta dell'API di Anthropic
>>> ciao claude!
{'type': 'message_start', 'message': {'id': 'msg_01XXXXXXXXXXYYYYYYY', 'type': 'message', 'role': 'assistant', 'content': [], 'model': 'claude-3-opus-20240229', 'stop_reason': None, 'stop_sequence': None, 'usage': {'input_tokens': 11, 'output_tokens': 2}}}
{'type': 'content_block_start', 'index': 0, 'content_block': {'type': 'text', 'text': ''}}
{'type': 'ping'}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'C'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'iao'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': '!'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': ' È'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': ' un'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': ' p'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'iac'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'ere'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': ' co'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'nos'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'ce'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'rti'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': '.'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': ' Come'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': ' pos'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'so'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': ' ai'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'ut'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'a'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': 'rti'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': ' oggi'}}
{'type': 'content_block_delta', 'index': 0, 'delta': {'type': 'text_delta', 'text': '?'}}
{'type': 'content_block_stop', 'index': 0}
{'type': 'message_delta', 'delta': {'stop_reason': 'end_turn', 'stop_sequence': None}, 'usage': {'output_tokens': 26}}
{'type': 'message_stop'}Come usare GPT-4-vision (Custom SSE Client)
Il codice che abbiamo scritto per comunicare con Claude 3 può essere facilmente adattato per comunicare con i modelli di OpenAI, Mistral, Google, Cohere...
Il codice qui sotto serve per comunicare con GPT-4-vision di OpenAI, capace di analizzare immagini inviate dagli utenti. Possiamo far analizzare immagini hostate in rete, passando al modello l'url dell'immagine, oppure inviare le nostre immagini.
Come inviare immagini: encoding Base64
Per inviare le nostre immagini dobbiamo anzitutto effettuarne l'encoding in base64, utilizzando l'omonimo package della Standard Library.
Nel codice qua sotto, oltre ad effettuare l'encoding tramite la funzione encode_image(), utilizziamo anche la funzione generate_encoded_image_url() per presentare l'encoding base64 con una formattazione consona all'invio.
# image_encoder.py
import base64
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
def generate_encoded_image_url(base64_image: str) -> str:
return f"data:image/jpeg;base64,{base64_image}"
if __name__ == "__main__":
image_path = "/percorso/che/porta/alla/vostra/immagine.png"
encoded_image = encode_image(image_path=image_path)
print(encoded_image)Oltre ad aver cambiato i valori di api_endpoint, model_name e headers (notate l'API key inviata tramite header Bearer), notiamo a colpo d'occhio come cambi anche la formattazione di ogni messaggio con role: user. La sezione relativa a content disporrà ora sia della parte testuale, che di quella relativa all'invio dell'immagine.
Cambiando anche il formato di ogni singolo chunk dello stream ricevuto dall'API dovremo conseguentemente cambiare il modo in cui i singoli pezzi della risposta vengono cercati (i.e. reperiti da chiavi diverse del dizionario ottenuto da json.loads()) e mostrati.
Nota importante: il codice qui scritto è pensato per scopi dimostrativi. L'immagine sta venendo inviata ad ogni nuovo messaggio testuale inviato dall'utente, mentre in contesti reali vorrete aggiungere un sistema di controllo più raffinato dove chiedere all'utente quale immagine si intende inviare.
# demo_api_oai_vision.py
import json
from sseclient import SSEClient
import requests
from auth_keys import get_api_key
from image_encoder import encode_image, generate_encoded_image_url
api_key = get_api_key("OPENAI_API_KEY")
image_path = "/percorso/che/porta/alla/vostra/immagine.png"
encoded_image = encode_image(image_path=image_path)
image_url = generate_encoded_image_url(base64_image=encoded_image)
api_endpoint = "https://api.openai.com/v1/chat/completions"
model_name = "gpt-4-vision-preview"
temperature = 0.0 # 1.0
headers = {
"Accept": "application/json",
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
chat_history = []
while True:
user_query = input(">>> ")
print()
# assicuratevi di modificare questa porzione di codice così che le immagini vengano inviate solo quando necessario
chat_history.append(
{
"role": "user",
"content": [
{"type": "text", "text": user_query},
{
"type": "image_url",
"image_url": {
"url": image_url
},
},
],
}
)
data = {
"model": model_name,
"messages": chat_history,
"temperature": temperature,
"stream": True,
"max_tokens": 2048 # potete variare!
}
response = requests.post(
api_endpoint,
headers=headers,
json=data,
stream=True
)
lm_response = ""
if response.status_code == 200:
stream = SSEClient(event_source=response)
for event in stream.events():
if event.data != "[DONE]":
delta_dict = json.loads(event.data)["choices"][0]["delta"]
if "content" in delta_dict.keys():
response_piece = delta_dict["content"]
lm_response += response_piece
print(response_piece, end="", flush=True)
chat_history.append({
"role": "assistant", "content": lm_response
})
else:
print(response.status_code)
print("\n")Come chattare con i modelli di Google, Mistral e Cohere (e qualche esempio di codice migliore)
Precisiamo nuovamente che, se non fosse ovvio, il codice scritto finora è pensato per scopri prettamente dimostrativi all'interno del tempo limitato di una presentazione YouTube. In contesti reali vorrete verosimilmente organizzare il tutto in maniera più elegante, modulare e mantenibile. Se siete interessati/e a visionare degli esempi di implementazione più concreti date uno sguardo al codice di un mio progetto chiamato TinyChat.
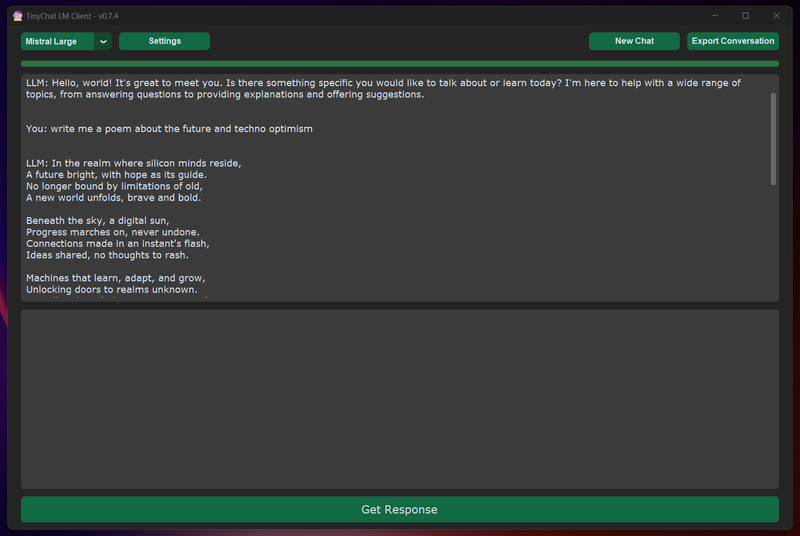
TinyChat è un semplice client desktop per large language model che supporta vari modelli offerti via Cloud API. Il codice che lo compone è organizzato in classi, ma dovreste comunque essere in grado di comprenderlo senza troppi problemi. Analizzando i moduli relativi a Cohere, Google e Mistral vedrete inoltre come sia possibile modificare il codice visto finora per chattare con i modelli offerti da queste aziende. Volendo potete anche scaricare le build pronte all'uso per Windows e Linux!
Precisiamo per completezza che esistono tanti client di questo tipo (anche se forse nessuno tanto minimalista) scaricabili con licenze più o meno permissive da GitHub.
Come usare modelli GGUF con Python (tramite Llama-Cpp-Python)
È finalmente arrivato il momento di vedere come sia possibile chattare con modelli linguistici open source in locale sui nostri computer personali o server. Questo ci permetterà di mantenere tutti i dati nei nostri dispositivi, con i numerosi vantaggi corrispondenti in termini di privacy e proprietà intellettuale. Oltre a ciò, usare dei modelli in nostro pieno possesso ci permette di costruire su basi solide, sapendo che il modello utilizzato non cambierà nel tempo, cosa che potrebbe invece accadere facendo affidamento sui modelli di terzi utilizzabili tramite API.
Anzitutto, precisiamo che il codice Python che vedremo permetterà l'impiego della modalità chat con i modelli linguistici predisposti in formato GGUF. Esistono anche altri formati per i modelli e altre modalità di interazione con questi, la cui analisi va però oltre lo scope di questa guida introduttiva.
GGUF è un formato binario progettato per il caricamento e il salvataggio veloci dei modelli, e per facilitarne la lettura. I modelli sono tradizionalmente sviluppati utilizzando PyTorch o un altro framework, e poi convertiti in GGUF per l'impiego. Potete scaricare modelli in formato GGUF da HuggingFace.
Se avete a disposizione una macchina con risorse considerevoli, in termini soprattutto di RAM e GPU, vi consigliamo di seguire questo esempio usando il modello di Mistral Mixtral 8x7B Instruct, che come potete vedere dallo screenshot sopra postato ha un punteggio Elo superiore a GPT-3.5! Potete scaricarlo dal profilo di TheBloke a questo indirizzo.
Se avete invece una macchina con risorse più limitate, vi consigliamo di utilizzare il modello Mistral 7B Instruct 0.2, scaricabile da questo indirizzo.
Come vedete per ogni modello sono presenti più versioni: da Q2_K a Q8_0, passando per Q4_0, Q5_K_M e così via. Notate come i modelli Q2 siano più leggeri dei modelli Q8. Queste "sigle" fanno infatti riferimento al processo di quantizzazione impiegato in fase di creazione dei file.
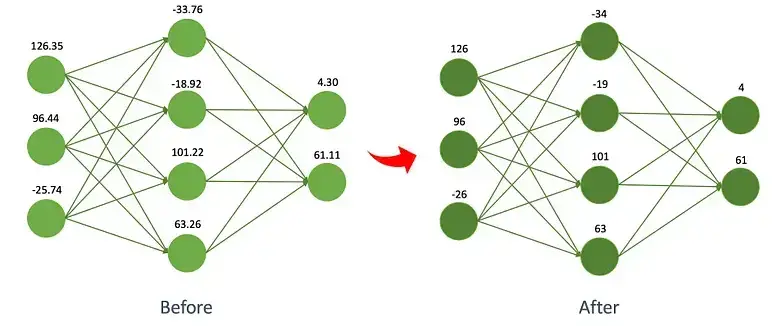
La quantizzazione è una tecnica utilizzata per ridurre le dimensioni degli LLM e la potenza di calcolo necessaria per eseguirli, permettendone così l'impiego su più dispositivi. La quantizzazione funziona convertendo i pesi della rete addestrata in valori a precisione inferiore. Secondo vari test riscontrabili in rete, Q5 rappresenta un buon compromesso tra performance e accuratezza. Nel video viene utilizzato il modello mistral-7b-instruct-v0.2.Q2_K.gguf, che ne permette l'impiego nonostante le risorse impiegate per la registrazione stessa del video e l'impiego degli strumenti del caso (browser, editor, doppio schermo).

Analizziamo ora il codice. Per farlo girare dovrete anzitutto installare Llama-Cpp-Python; come sempre vi consigliamo di fare ciò all'interno di un ambiente virtuale. Non dovreste avere particolari problemi in fase di installazione, ma dovrete verosimilmente installare anzitutto qualche dipendenza a livello di sistema. In questa fase, vi consigliamo di tenere a portata di mano la documentazione ufficiale di llama-cpp-python e i dettagli presenti nel repo GitHub sopra linkato.
Importiamo anzitutto la classe Llama dal package llama_cpp, così da poter inizializzare un oggetto che ci permetta di interagire col nostro modello GGUF. Per inizializzare un oggetto llm sarà sufficiente passare il percorso di sistema che porta al file. A seconda delle vostre necessità potreste dover / voler impostare uno o più parametri opzionali.
Noterete ora come il resto del codice sia molto simile a quanto visto finora con i modelli impiegati tramite cloud API. Questo perché ci stiamo dopotutto interfacciando col modello in modalità chat!
Inizializziamo anzitutto una chat_history come una lista vuota e avviamo un ciclo infinito. Dentro al ciclo invochiamo il metodo create_chat_completion() della classe Llama, specificando la chat_history come valore per il parametro messages, stream = True, e un valore a scelta nel range 0.0 - 1.0 per temperature. Potremo quindi ciclare per tutti i chunk dello stream, ottenendo da questi i pezzetti della risposta generata dal LLM, da mostrare all'utente e usare per comporre la risposta, da aggiungere alla chat_history.
# gguf_models.py
from llama_cpp import Llama
model_path = "/percorso/che/porta/al/file/mistral-7b-instruct-v0.2.Q2_K.gguf"
llm = Llama(model_path=model_path)
chat_history = []
while True:
user_query = input(">>> ")
chat_history.append({
"role": "user", "content": user_query
})
stream = llm.create_chat_completion(
messages = chat_history,
stream=True,
temperature=0.0
)
lm_response = ""
for chunk in stream:
if "content" in chunk["choices"][0]["delta"].keys():
response_piece = chunk["choices"][0]["delta"]["content"]
lm_response += response_piece
print(response_piece, end="", flush=True)
chat_history.append({"role": "assistant", "content": lm_response})Come andare oltre? Note sugli strumenti per creare app strutturate
A questo punto, qualcuno/a tra voi si starà chiedendo come sia possibile andare oltre il semplice formato chat per poter creare applicazioni più strutturate.
Potreste ad esempio voler accedere a sorgenti dati esterne, in modo da aumentare la capacità generativa dei modelli andando oltre quanto da questi appreso durante le fasi di training, riducendo così le "allucinazioni" in senso stretto.
Oppure potreste voler salvare le vostre conversazioni in modo tale che il modello le "ricordi" e possa farci riferimento per quelle future.
Magari volete creare degli "agenti" capaci di comprendere le vostre richieste ed eseguire azioni specifiche, in concerto con qualche servizio di terze parti.
In casi come questi è bene dare uno sguardo a framework specializzati pensati proprio per casi come questi piuttosto che reinventare la ruota.
Vi consigliamo di provare LangChain, LamaIndex e Cheshire Cat. Happy Coding!
NOTE FINALI EXTRA GUIDA: nella parte finale del video faccio riferimento ad un nuovo corso Academy in fase di uscita. Come dico anche nel video, sarà possibile iniziare a iscriversi a partire dai prossimi giorni. Come tutti gli altri corsi Academy, anche questo sarà accessibile via streaming on demand, e fino al suo completamento sarà offerto ad un prezzo speciale (le lezioni già pronte saranno disponibili da subito). Per essere informati/e all'uscita, iscrivetevi alla developers newsletter!